

























De cómo con ciencia de datos puedes predecir vía X resultados de una elección

A partir de 2021, un grupo de investigadores, comunicadoras políticas, lingüistas y especialistas en ciencia de datos de la Universidad Iberoamericana CDMX, y liderados por el Dr. Ulises Cruz, diseñaron un algoritmo no supervisado que lee lenguaje natural para identificar postura de voto de los usuarios en Twitter.
Una primera versión de este dispositivo fue probada con un conjunto de prueba de 5 mil tweets en el contexto de las elecciones presidenciales de 2018, donde contendieron: Andrés Manuel López Obrador, Ricardo Anaya y José Antonio Meade.
Tras el ejercicio, el algoritmo arrojó una coincidencia perfecta en las posiciones que estos candidatos obtuvieron respecto de la votación final. Como lo muestra la siguiente gráfica, Andrés Manuel López Obrador quedó en primer lugar, seguido de Ricardo Anaya y José Antonio Meade.
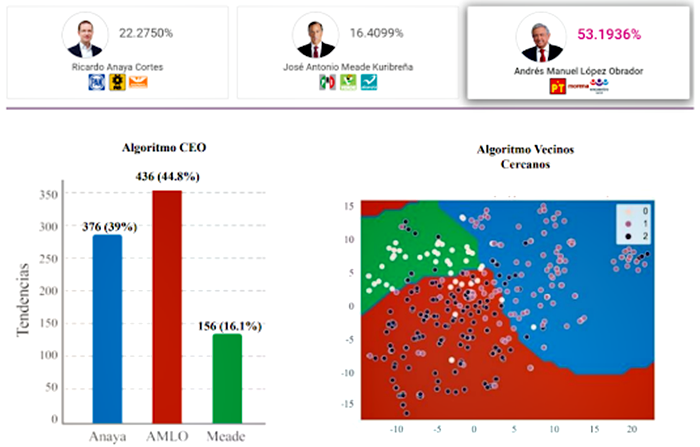
Tal y como se aprecia en la imagen anterior, y con el objetivo de verificar nuestros resultados, el mismo conjunto de datos se puso a prueba en un algoritmo supervisado de Machine Learning denominado K-Vecinos Cercanos (K-Nearest Neighbors). Después de procesarlos, encontramos que ambos algoritmos coincidieron con la tendencia electoral final de dicha elección presidencial.
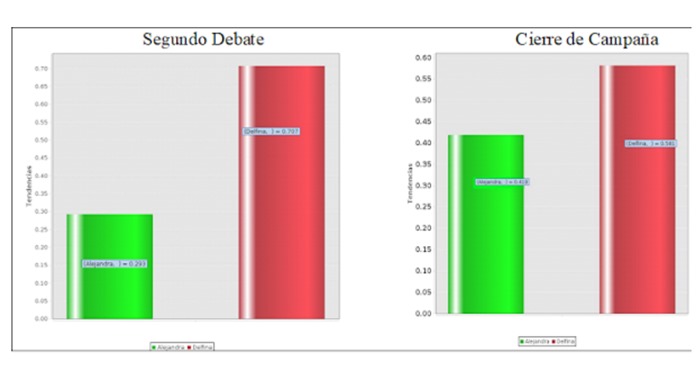
Hecho lo anterior, se procedió a aplicar el algoritmo en un nuevo conjunto de mensajes, pero esta vez sobre una base de 90 mil tweets provenientes de los debates y cierres de campaña de la gubernatura del Estado de México en el 2023. Concluido el primer debate, nuestro algoritmo reportó en tiempo real que la morenista Delfina Gómez se ubicó en el primer lugar de las preferencias electorales, mientras que Alejandra del Moral, de la coalición PRI-PAN-PRD, en el segundo.
El segundo debate y el cierre de campaña no mostraron cambios en las posiciones de las candidatas, por lo que, al término de la prueba, concluimos una vez más que el algoritmo no presenta sesgo de probable ganador, aunque sí una baja precisión dado el número de tweets analizados.
Esto, de acuerdo con estudios previos, se debe a que los tweets analizados se encuentran por debajo del millón de unidades. En la literatura especializada, incluso, hay algoritmos de este tipo que han reducido sus márgenes de error hasta 0.5% con tres millones de tweets clasificados.
Para probarlo, nuestro equipo de investigación aplicará este algoritmo durante las elecciones presidenciales de 2024 para verificar si, efectivamente, la precisión se incrementa conforme lo hace el número de unidades analizadas.
|
Más información en el blog TODO ES DISCURSO, en el que, desde una mirada más científica, se observa el discurso político en campaña para abonar al perfeccionamiento de las decisiones públicas y la formación cívica |
- Visita nuestro sitio Encuentros por la democracia / #IBERODialoga
Notas de interés
- Medirá IBERO mediante emojis emociones en el contexto
- Desarrolla IBERO algoritmo de predicción del voto en Twitter
- #ANÁLISIS Redes sociales serán la nueva arena electoral
Especialistas de la IBERO en medios
- PAN, PRI y PRD definen candidaturas al Congreso (Análisis de Ivonne Acuña en El Economista)
- Para AMLO el sexenio terminó en materia de seguridad (Ernesto López Portillo en La Zeta Noticias. 107.3 FM)
- Desafortunada le parece a Gutiérrez Márquez la ausencia de independientes (Debate - Sinaloa)
Las opiniones y puntos de vista vertidos en este comunicado son de exclusiva responsabilidad de quienes los emiten
y no representan necesariamente el pensamiento ni la línea editorial de la Universidad Iberoamericana.
Para mayor información sobre este comunicado llamar a los teléfonos: (55) 59 50 40 00, Ext. 7594, 7759
Comunicación Institucional de la Universidad Iberoamericana Ciudad de México
Prol. Paseo de la Reforma 880, edificio F, 1er piso, Col. Lomas de Santa Fe, C.P. 01219



















