

























Desarrolla IBERO algoritmo de predicción del voto en Twitter
") Los doctores Mauricio Flores y Ulises Cruz al presentar el algoritmo CEO. (Foto: Yazmín Mendoza)
Los doctores Mauricio Flores y Ulises Cruz al presentar el algoritmo CEO. (Foto: Yazmín Mendoza)") Dr. Mauricio Flores Gerónimo, académico de la Ingeniería en Ciencia de Datos que está por estrenarse en la Universidad Iberoamericana. (Foto: Yazmín Mendoza)
Dr. Mauricio Flores Gerónimo, académico de la Ingeniería en Ciencia de Datos que está por estrenarse en la Universidad Iberoamericana. (Foto: Yazmín Mendoza)") Dr. Ulises Cruz Valencia, académico del Departamento de Comunicación. (Foto: Yazmín Mendoza)
Dr. Ulises Cruz Valencia, académico del Departamento de Comunicación. (Foto: Yazmín Mendoza)
Un equipo multidisciplinario de investigadores e investigadoras de nuestra IBERO y de la UNAM diseñaron un algoritmo de análisis y predicción del voto que ha obtenido resultados altamente precisos, tanto en la elección presidencial de 2018, como en el primer debate de las elecciones del Estado de México de este año.
Uno de los mayores logros, explicó en conferencia el Dr. Ulises Cruz Valencia, académico del Departamento de Comunicación de la Ibero, fue el poder replicar con éxito este modelo que se probó por primera vez en 2018, pues el volumen de tuits analizados pasó de 3 mil 384 tuits hace cinco años a 40 mil en 2023. Aunque tenían un plan de respaldo, la programación en el lenguaje orientado a objetos Java con el que se creó el algoritmo resultó ideal, explicó el Dr. Mauricio Flores Gerónimo, académico de la Ingeniería en Ciencia de Datos que está por estrenarse en la Universidad Iberoamericana.
El objetivo a largo plazo del proyecto CEO --llamado así en honor del titán de la inteligencia y la sabiduría-- es analizar de uno a dos millones de tuits en las elecciones de 2024. Por ahora, el equipo se propone analizar el siguiente debate entre Delfina Gómez y Alejandra del Moral, así como el cierre de campaña, que son las ventanas que han identificado en donde la manifestación de la intención del voto en redes sociales es más recurrente.
La relevancia de este proyecto, destacó el Dr. Flores, es que el algoritmo CEO no es una biblioteca que ya está diseñada, sino que “lo estamos codificando de acuerdo a las necesidades que nos van indicando las y los lingüistas” que forman parte del proyecto; es decir, no se basa en criterios ya establecidos, sino que están creando los propios a la medida para este contexto específico.
Además, al detectar tanto opiniones positivas como negativas, este algoritmo permitió al equipo darse cuenta de que la persona candidata con más opiniones positivas suele recibir también la mayor cantidad de opiniones negativas, lo cual funciona como una variable de control.
En el caso de la elección presidencial de 2018, este algoritmo basado en Twitter dio un 44.8% de preferencia de voto a Andrés Manuel López Obrador, 39% a Ricardo Anaya y 16.1% a José Antonio Meade. Al finalizar la elección, se pudo comprobar que esta predicción fue cercana a los resultados reales, de 53.19% para López Obrador, 22.27% para Anaya y 16.4% para Meade.
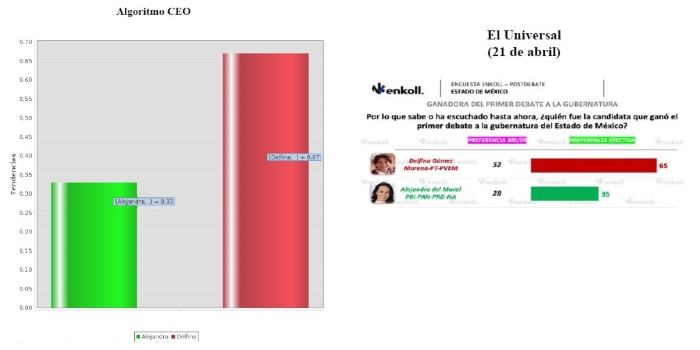
Durante el primer debate de las actuales elecciones del Estado de México, el algoritmo fue aún más preciso, pues predijo una preferencia de 67% para Gómez y de 33% para Del Moral, y estos datos se aproximaron mucho a los de una encuesta de Enkoll publicada por El Universal al día siguiente: 65% para Gómez y 35% para Alejandra.
De la recolección de datos a la clasificación
Para este análisis de contenido cuantitativo se elaboró un libro de codificación, una matriz para vaciado de datos, un manual de entrenamiento y una bolsa de palabras para que estudiantes de posgrado y licenciatura pudieran codificar esas categorías, pues se necesitó contextualizar al algoritmo con cada palabra de cada tuit.
El Dr. Manuel Alejandro Guerrero Martínez, académico e investigador del departamento de Comunicación, detalló que los tuits explícitos se caracterizan por un conjunto de expresiones que se asocian de manera directa con una intención u opinión, mientras que para detectar los implícitos hay que revisar la estructura lingüística, quitarle la superficie para inferir la intención de voto.
Con esta información se establecieron los criterios para que el algoritmo pudiera distinguir de manera automática entre tuits explícitos e implícitos, así como etiquetarlos como positivos o negativos para finalmente elaborar una gráfica. En el ejercicio de 2018 se trabajó con un set inicial de 3 mil 384 tuits. De ellos, mil 234 se etiquetaron con una postura de voto explícita y otros mil 622 se etiquetaron con postura de voto implícita; estos datos fueron los que se utilizaron para construir la gráfica, mientras que mil 28 tuits quedaron fuera porque no ofrecían información de tendencia de voto.
Representatividad de los datos
Los datos de este proyecto reflejan la tendencia de la elección en un conglomerado determinado de tuits, no son representativos del territorio, advirtieron los investigadores. “Para tener una total representatividad, cada mexicano debería tener una cuenta de Twitter y manifestar su preferencia electoral”, agregó el Dr. Cruz. Sin embargo, admitió que muchas veces la red social se comporta de una manera similar al territorio. Es decir, aunque no tienen representatividad estadística, muchas veces los resultados son similares a lo final.
Una segunda parte del proyecto se relacionará con emociones discretas en las elecciones, tales como enojo y angustia, lo cual puede ser complicado por fenómenos como la ironía al escribir. Así, se vería cómo esta parte emocional se conecta con la parte de la decisión de las y los usuarios. Y más adelante, explicaron los investigadores, los datos se podrían desagregar en otras variables de interés, como arquetipos de usuario.
Texto y Fotos: Yazmín Mendoza
Notas relacionadas:
- La IBERO celebra el ‘Día de las Ingenierías’ entre robots, procesadores y muchas ideas
- ¿Storytelling y ciencia de datos? ¡Así se pueden contar historias con números!
- Dalia Ramírez: de soñar con el Universo a trabajar en el CERN
Las opiniones y puntos de vista vertidos en este comunicado son de exclusiva responsabilidad de quienes los emiten
y no representan necesariamente el pensamiento ni la línea editorial de la Universidad Iberoamericana.
Para mayor información sobre este comunicado llamar a los teléfonos: (55) 59 50 40 00, Ext. 7594, 7759
Comunicación Institucional de la Universidad Iberoamericana Ciudad de México
Prol. Paseo de la Reforma 880, edificio F, 1er piso, Col. Lomas de Santa Fe, C.P. 01219



















